Description
The Spark KNN Score process type provides the ability to configure and productionize custom Spark K-Nearest Neighbors scoring code into a Syntasa Composer workflow. By configuring this process it is allowing Syntasa to manage the KNN model scoring on a scheduled basis. A user will find that there are two ways of importing the code:
- Paste into a text editor window
- Upload a file with the code
After placing the code into text editor, the output locations of the process type will need to be specified.
Once the process is configured and tested it can be deployed to production, and scheduled for Syntasa to run on a scheduled basis.
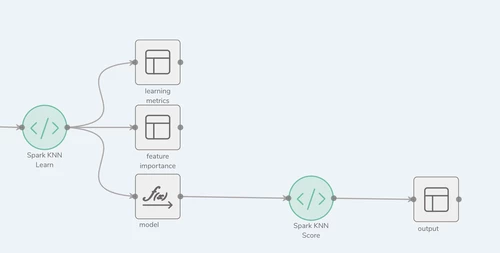
Process Configuration
There are two screens that need configuring for this process type.
- Parameters
- Output
Parameters
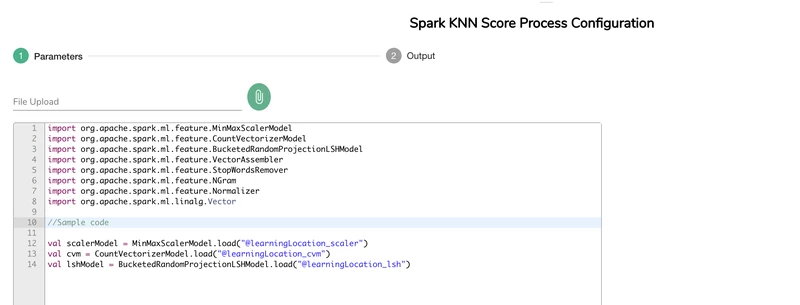
The Parameters screen is where the actual custom code is imported by either pasting or file upload.
File Upload
- Click the
 icon
icon - A file browser window will appear
- Select the file with the code to be imported
- Click Open
- The contents of the file will be placed in the text editor window
- Also, the file name will be displayed just below the "File Upload" heading
Output
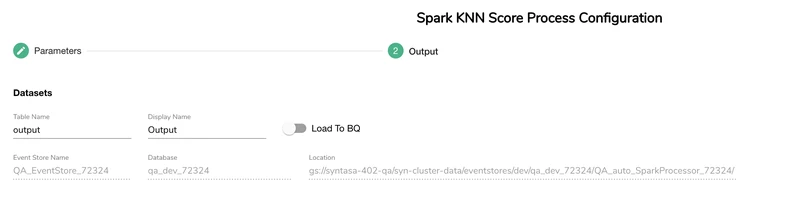
Output screen is where the table name can be defined along with the option to "Load to BQ" when using Google Cloud Platform or "Load to Redshift" when using Amazon Web Services. There only output at this time for this process is a dataset.
Expected Output
The expected out of this process type is the scoring dataset table that is produced by the custom code imported into the Parameters screen. This custom code output dataset will be written to a table in the environment the code was run (i.e. BigQuery, Redshift).