When dealing with different data science use cases, we come across different kinds of variables such as strings, numbers, or text data. Datasets usually have a mix of categorical and continuous variables. However, algorithms that are powered by these datasets understand only numbers. Hence, it is important to convert and transform all the variables into numbers which can then be fed into an algorithmic model. Additionally, these transformations on source data also act as foundation datasets for feature engineering which one of the most fundamental aspects of machine learning.
Feature Learn and Feature Transform processes enable users to perform Extraction, Transformation, and Feature Selection using Spark-based algorithms. These features allow users to work with different data types such as string and numeric but also help them convert these features into vector representations. These feature vectors can then be used in machine learning models in downstream processes for different use cases. Read more about them here: https://spark.apache.org/docs/latest/ml-features.html
These processes are available for users in the Syntasa environment from version 4.2 and forward.
Why do we need two processes?
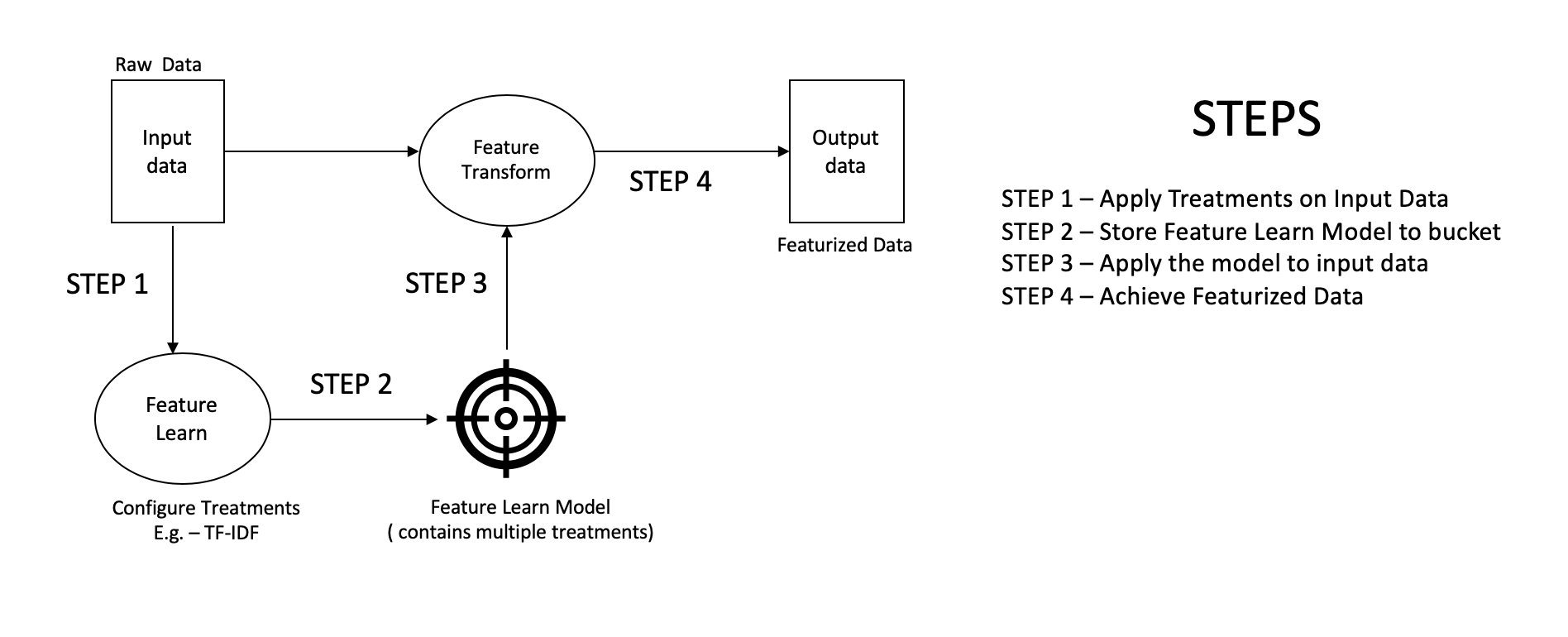
The Feature Learn process is responsible for fitting a model to a raw dataset. This model is a recipe in a way that is used in the Feature Transform process where the raw data gets transformed into featurized data.
The Feature Learn process should only be used during the training phase. During the training phase, a model, which consists of different treatments on different variables, is saved to the cloud bucket.
Th Feature Transform process is used during training as well as the scoring phases. During the training and scoring phases, the model is loaded from the cloud bucket and is applied to raw input data to get featurized data. This data, as mentioned above, becomes ML ready after Feature Transform is applied.
Capabilities
- Users can configure a chain of treatments in a single Feature Learn process.
- For example, the raw string data type can undergo all of the treatments as a bunch of steps chained together: regex tokenizer → stop word remover → count vectorizer → PCA.
- Easier to isolate FIT and TRANSFORM processes.
- It allows users to use the order of treatments as required. Steps in the treatment can be ordered in any way, as long as they create valid data types.
Example workflow
Here is a screenshot showing a sample workflow canvas:
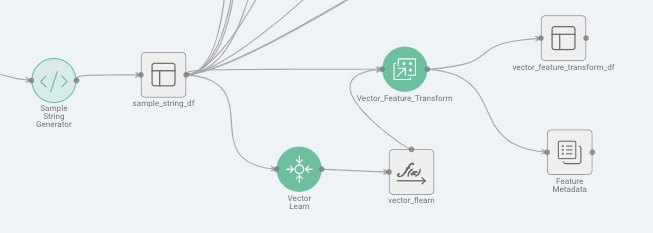
- sample_string_df - This is the raw input data.
- Vector Learn - This is the Feature Learn process. It generates a model that is saved to a bucket.
- Vector _Feature _Transform - This is the Feature Transform process. This process takes input data and applies the learned model to the input data.
- vector_feature_transform_df - This is the output Featurized data. Notice that this process also generates Metadata for the user.
What is a treatment?
Any transformation on a field/column/variable is called a treatment. A treatment can contain more than one step. Each step represents a transformation of some kind. Steps are driven by methods that have parameters or settings which enable users to transform the data.
Example treatment
Below is an example of Principal Component Analysis (PCA) treatment that is configured on the numeric type column one_hot_encode:
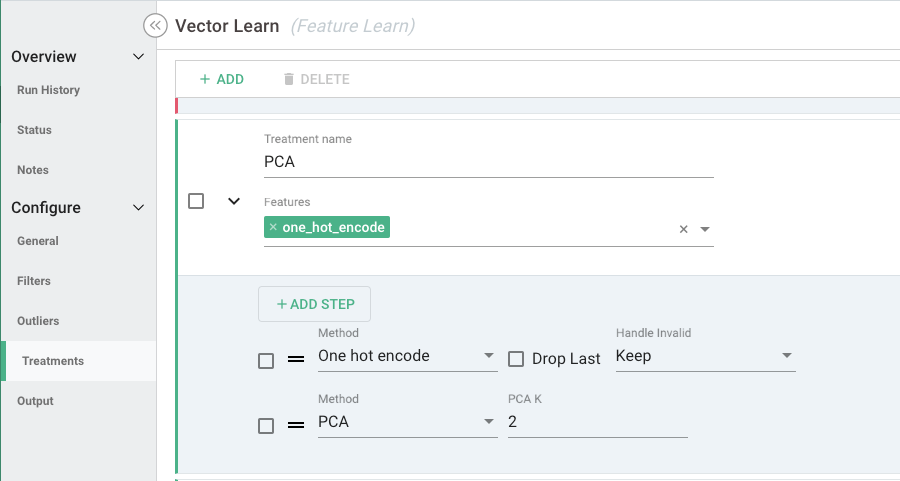
- Treatment name - Name of the treatment given by the user.
- Features - Columns that users can choose for applying the treatment. More than one column can be selected.
- Steps:
- Method 1: One hot encode - This method converts Numeric Type N1 to Vector Type V1.
- Method 2: PCA - This method converts the Vector Type V1 (from the above method) to a transformed Vector Type V2.
- Parameters - Each step has a parameter or a setting that enables the transformation. For example, method PCA takes an input K that is the number of principal components.
Chaining treatments
Since treatments can be applied to any INPUT data type, it is necessary for the user to understand the available treatments. Logical chaining is the set of steps in the treatments that cannot be chained randomly. Chaining is allowed when the steps fall into a logical plan of the overall chain.
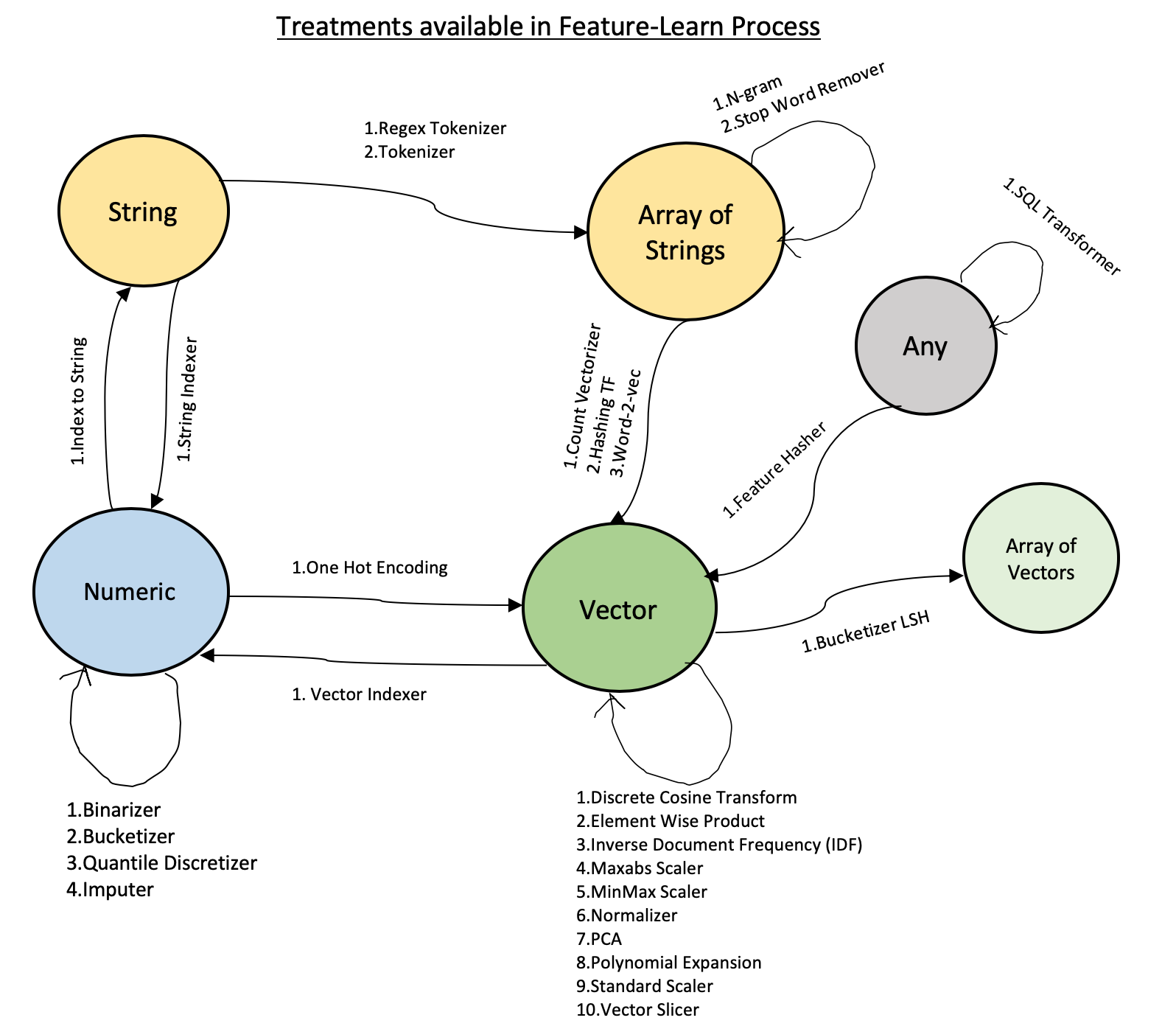
The graph below shows what treatment can be applied to every possible data type in the input data:
- Each node N of the graph represents the input data type.
- Every edge E of the graph shows which treatments can be applied to that particular data type.
- Arrows Ai represents the transformation of input data to another intermediate output data type.
- Edges that connect a node N to itself denote that input and output data types are the same. For example, the n-gram treatment takes an array-of-strings as input and creates an array-of-strings in the output.
Example - Consider you have a TEXT input data. In this scenario, if you want to represent this string into a vector format then you would want to take below approach:
- Start with an input string.
- Convert string into array-of-strings using Tokenizer treatment.
- Convert array-of-strings into feature vectors using Word-2-Vec treatment.
- End with output as a vector representation of input TEXT.