The Unified Event Enrich process takes the data in raw and enriches and transforms it to follow the SYNTASA schema as defined in the configuration mapping unique to each data source.
Process Configuration
The Unified Event Enrich process includes four screens providing the ability to join multiple datasets, map to the schema, apply desired filters, and understand where the data is being written. Below are details of each screen and descriptions of each of the fields.
Click on the Unified Event Enrich node to access the editor.
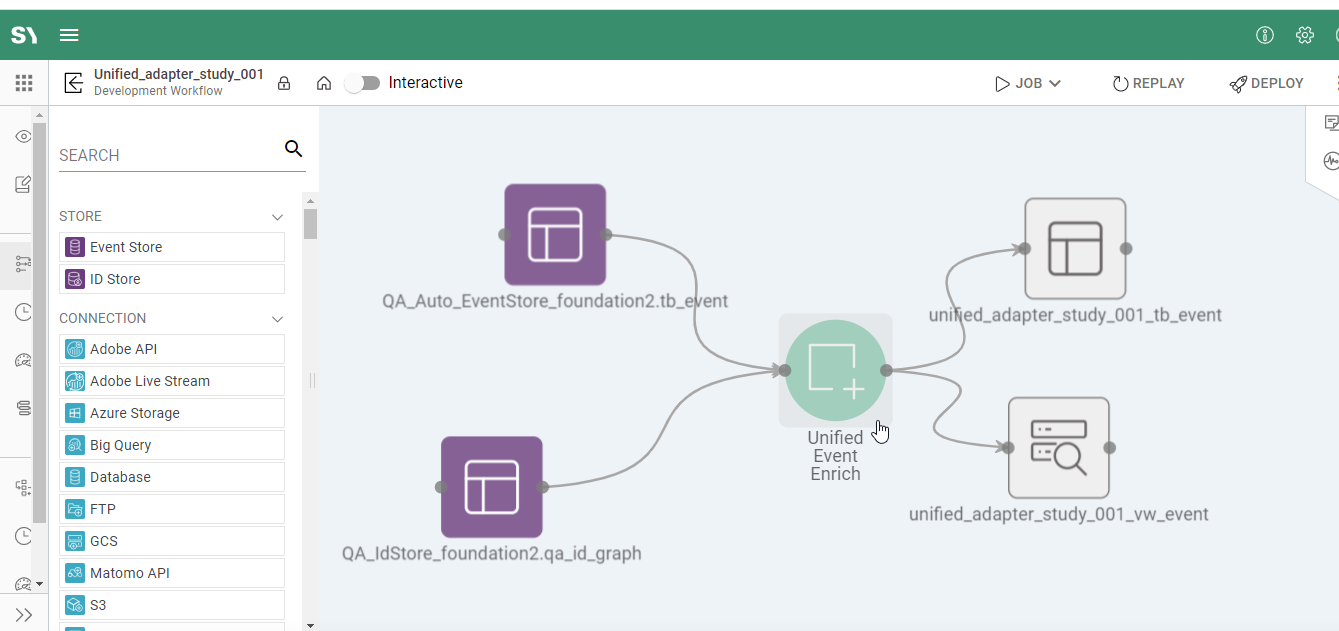
Join
This section provides the information Syntasa needs if more than one set of data will be joined. To create a join, click the green plus button.
- Join Type - Left or inner join at this time
- Dataset selector - Choose the dataset that will be joined with the first dataset
- Alias - Type a table alias if a different name is desired or required
- Filter Join - This is not needed here. A filter is needed for
- Avoids reading of unnecessary data from the lookup table.
- It is beneficial only when the lookup (secondary table ) is big.
- It helps spark perform some optimization while doing product/event enrich.
- It extracts only values(let's say Product ID) that are present in the main table from the lookup table and performs the join.
- Left Value - Choose the field from the first dataset that will provide a link with the joined dataset (i.e. customer ID if joining a CRM dataset)
- Operator - Select how the left value should be compared with the right value, for a join this will typically be a = sign
- Right Value - Select the joining dataset value that is being compared with the left value
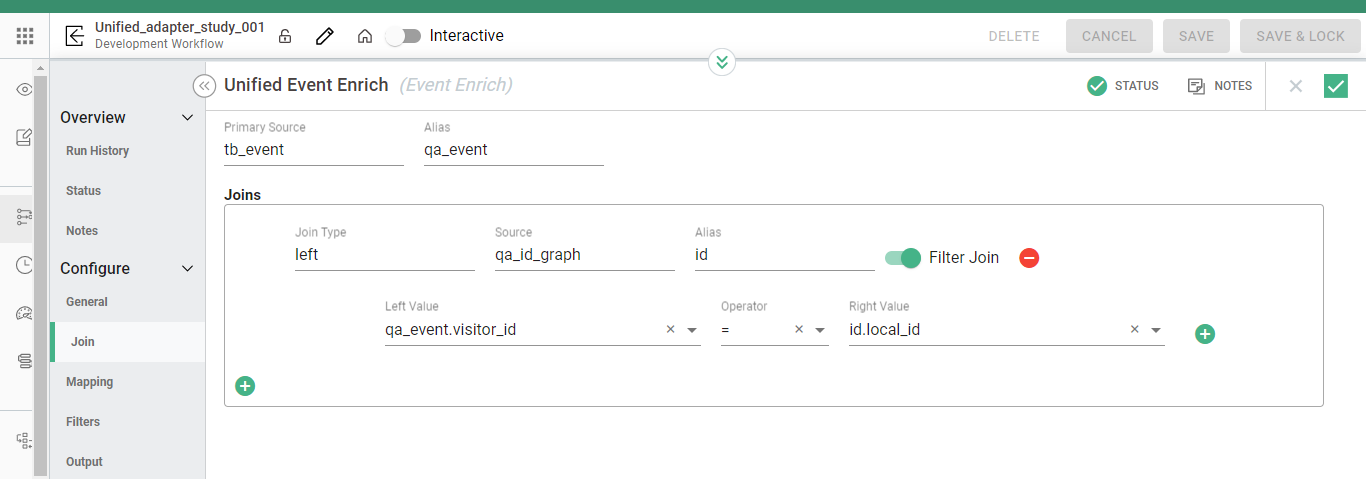
Mapping
The table is where the event data is defined and labeled into the Syntasa schema. Syntasa has a growing set of custom functions that can be applied along with any Hive functions to perform data transformation. It is best to consult Syntasa consulting before applying functions.
- Field - fixed Syntasa table column labels
- Label - customizable user-friendly names
- Function - This is where we write our enrichment, this can be one of the following:
- You can write custom logic like regex or a case statement.
- Combining columns into one column. For example, customer_name might be cust_name in one report and first_name in another. In unified we can combine these as we will have one column for both report suites that we might call customer_name. This would be achieved by typing report_name.field_name_in_source
Actions
For Unified Event Enrich there are two options available: Import and Export. Import is selected if there is no API process configured but the client has JSON data available to provide the custom mappings. Export is utilized to export the existing mapping schema in a .csv format that can be used to assist in the editing or manipulation of the schema. This updated file could then be used to input an updated schema into the dataset
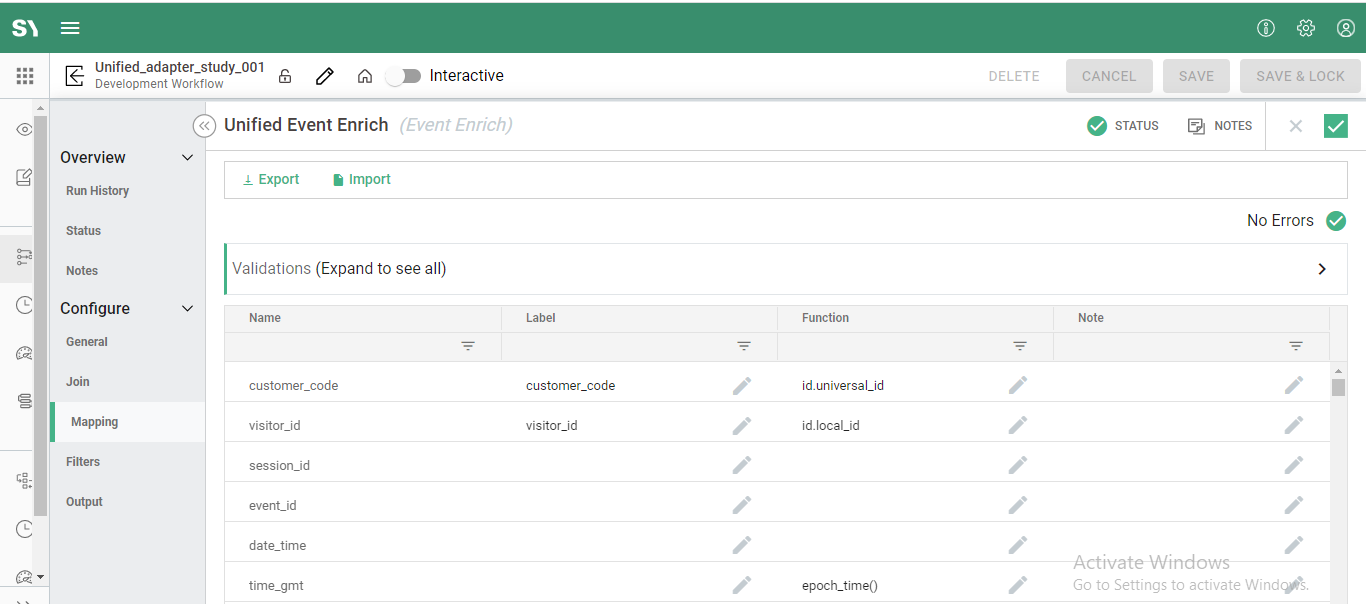
Filters
Filters provide the user with the ability to filter the dataset (apply a Where clause).
To create a filter:
- Click the green plus button
- Filter editor screen will appear
- Ensure the proper (AND/OR) logic is applied
- Select the appropriate Left Value from the drop-down list or click --Function Editor-- to create and apply a custom function
- Select the appropriate Operator from the drop-down list
- Select the desired Right Value for the filter from the drop-down list or click --Function Editor-- to create and apply a custom function
- Multiple filters can be created and applied
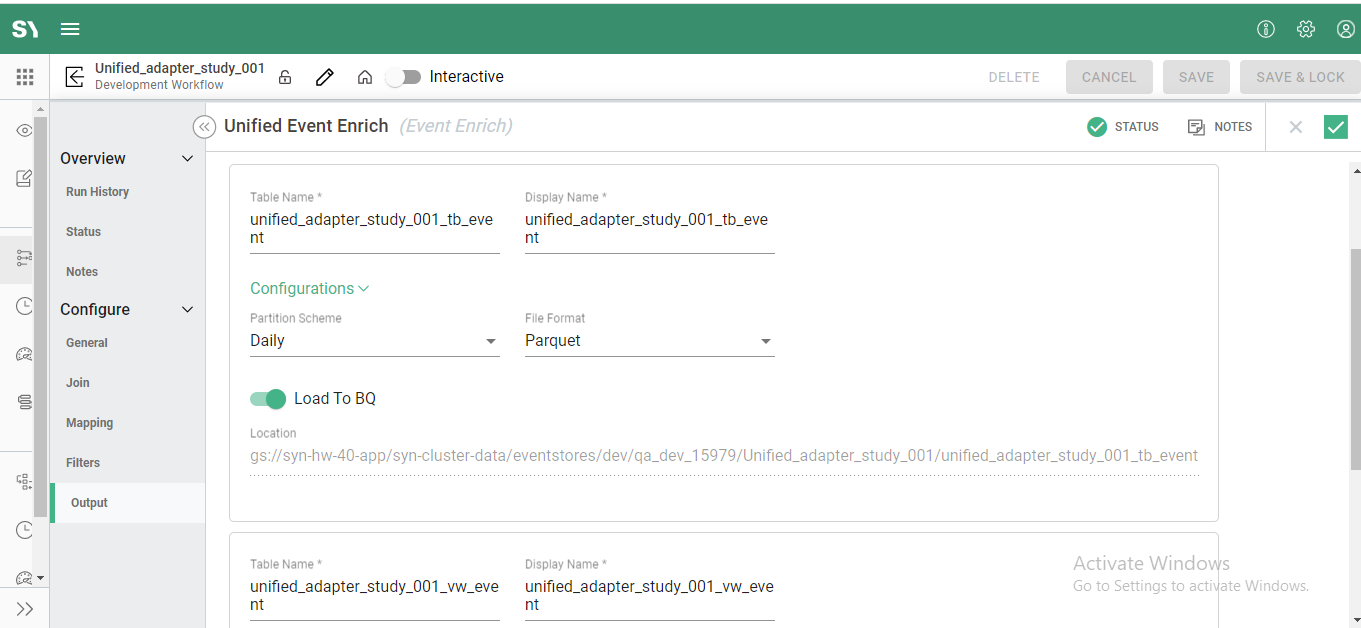
Outputs
The Outputs tab provides the ability to name tables and displayed names on the graph canvas, along with selecting whether to load to Big Query (BQ) if in the Google Cloud Platform (GCP), load to Redshift or RDS if in Amazon Web Services (AWS), or simply write to HDFS if using on-premise Hadoop.
- Table Name - defines the name of the database table where the output data will be written. Please ensure that the table name is unique to all other tables within the defined Event Store, otherwise, data previously written by another process will get overwritten
- Display Name - The label of the process output icon displayed on the app graph canvas.
- Configurations
- Partition Scheme - Defines how the output table should be stored in a segmented fashion. Options are Daily, Hourly, None. Daily is typically chosen.
- File Format - Defines the format of the output file. Options are Avro, Orc, Parquet, Textfile
- Load To BQ - This option is only relevant to Google Cloud Platform deployments. BQ stands for Big Query and this option allows for the ability to create a Big Query table. If using AWS, this will have the option to Load To RedShift and if an on-premise installation data is normally written to HDFS and does not display a Load To option.
- Location - Storage bucket or HDFS location where source raw files will be stored for Syntasa Event Enrich process to use.
Now save the changes by clicking tick (![]() ) on the right.
) on the right.
Expected Output
The expected output of the Visitor Enrich process are the below tables within the environment the data is processed (e.g. AWS, GCP, on-prem Hadoop)
- tb_visitor_daily - visitor-level table using Syntasa defined column names
- vw_visitor_daily - view built off tb_event providing user-friendly labels
These tables can be queried directly using an enterprise-provided query engine and the tables can serve as the foundation for building other datasets, such as custom-built datasets.